Abstract: Nowadays, face recognition has more and more applications in real life. However, for some low resolution face images, how to accurately locate the facial feature points therein is a challenge. Recently, scientists at the Computer Vision Laboratory at the University of Nottingham, UK, proposed a Super-FAN, which is the first end-to-end system to integrate super-resolution of face and feature point location. It can improve the quality of low-resolution face images, and can also accurately locate face features on the image.
This article presents two challenging tasks: improving the quality of low-resolution face images and accurately locating face features on these low-resolution images. To this end, we made the following five contributions:
1. We proposed Super-FAN: the first end-to-end system that can solve both tasks at the same time, namely improving face resolution and detecting face feature points. The novelty of Super-FAN lies in the integration of structural information into a network by integrating a face alignment sub-network into heatmap regression and optimizing new heatmap losses. GAN-based super-resolution algorithm.
2. We have shown good results in both frontal images (as in previous studies) and overall face pose spectra, as well as in synthetic low-resolution images (as in previous studies) and in real-world images. The benefits of training these two networks.
3. We have improved the most advanced technology of face super resolution by proposing a new residual-based architecture.
4. Quantitatively, we have greatly improved the most advanced technologies for face super resolution and face alignment.
5. Qualitatively, we obtained good results for the first time on real-world low-resolution images, as shown in Figure 1.

Figure 1: Sample images of some of the visual effects generated by our system on a real low resolution human face from WiderFace.
The purpose of this article is to improve the quality and understanding of very low resolution face images. This is important in many applications, such as face editing monitoring/security. In terms of quality, our goal is to increase the resolution and restore the details of real-world low resolution face images, as shown in the first line of Figure 1. This task is also known as "face super. -resolution)" (When the input resolution is too small, the task is sometimes called "face hallucination").
In terms of understanding, we hope to use semantic meaning to locate a set of predefined face feature points (such as the tip of the nose, corners of the eye) to extract high-level face information; this task is also called "face alignment ( Face alignment)".
Trying to solve both tasks at the same time is actually a "chicken or egg" problem: On the one hand, the ability to detect facial feature points has been shown to be beneficial for face superresolution; however, how to pose in arbitrary poses The completion of the low-resolution face is still a problem to be solved. On the other hand, if low-quality and low-resolution human faces can be effectively resolved in the overall face pose spectrum, face feature points can be accurately located.
Because it is difficult to detect feature points in very low-resolution faces (as noted and verified in this study), previous super-resolution methods based on this idea generated when face feature points were poorly located. A blurred image with artifacts.
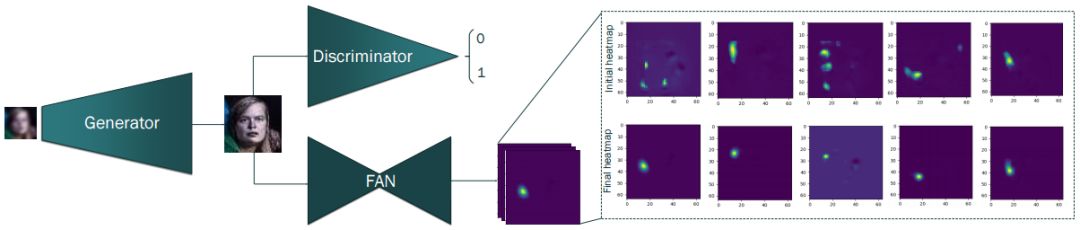
Figure 2: The Super-FAN architecture proposed in this paper contains three connected networks: The first is the just-proposed super-resolution network. The second network is a WGAN-based discriminator for distinguishing between super-resolution and original HR images. The third network is FAN, which is a face-aligned network for locating facial feature points on super-resolution face images and improving super-resolution through newly introduced heat map distortion.
Our main contribution is to prove that even for completely arbitrary gestures (for example, avatar images, see Fig. 1 and Fig. 5), it is actually possible to jointly perform facial feature point positioning and super-resolution,
In summary, our contribution is:
1. We proposed Super-FAN: the first end-to-end system that can simultaneously resolve face super resolution and face alignment. It integrates the facial feature localization sub-networks into GAN-based super-resolution networks through heatmap regression and incorporates new heatmap losses. See Figure 2.
2. We show the benefits of the synthesizing of arbitrary face poses and the training of these two networks on real world low resolution human faces.
3. We also propose an improved residual-based super-resolution architecture.
4. Quantitatively, we report for the first time the results of the global face pose spectrum on the LS3D-W data set and show great progress in super-resolution and face alignment.
5. Qualitatively, for the first time we get good visual effects on real-world low resolution face images obtained from the WidFace dataset (see Figures 1 and 5).
Next, we will introduce related research on image and face super-resolution and facial landmark localization.

Figure 3: Comparison between the super-resolution architecture proposed in this article (left) and the architecture (right) described in "Using Generating Against Photorealistic Single Image Super Resolution for Network Implementation".
Image super resolution
Early super-resolution attempts using CNN used standard Lp loss training, resulting in ambiguous super-resolution images. In order to alleviate this problem, the author of the paper "Perceived loss of real-time style transition and super-resolution" proposed an MSE on feature mapping, which proposes perceptual loss rather than on pixels (super-resolution and reference Between real HR images) use MSE. It is worth noting that we also use perceptual loss in our approach.
Recently, in "Using Generic Photorealistic Single Image Super Resolution for Network Implementation," the authors propose a GAN-based method that uses discriminators between super-resolution and original HR images and perceptual loss. distinguish. In "Enhancenet: Single image superresolution by automatic texture synthesis", the author proposes a patch-based texture loss to improve reconstruction quality.
It is worth noting that all of the image super-resolution methods mentioned above can be applied to all types of images and therefore do not include face-specific information, as proposed in our study. In addition, in most cases, the goal is to generate high-fidelity images with good resolution (usually 128×128) for a given image, while the facial super-resolution method usually has very low resolution (16× The result of the report is given on the face of 16 or 32 x 32).
From all of the above methods, our research is more closely related to "Real-Time Style Migration and Perceptual Loss in Super-Resolution" and "Using Generating Photo-Realistic Single Image Super Resolution for Network Implementation." In particular, one of our contributions is to describe an improved GAN-based super resolution architecture that we use as a strong baseline on which to build our integrated face super resolution and alignment network. (alignment network).
Face resolution
Recently, in the study of "Ultra-super-resolution face images realized through a discriminative generative network", a GAN-based method was used to distinguish face images with very low resolution. This method shows that the front and pre-aligned faces from the CelebA dataset run well.
In “Unaligned and noisy face images with extremely low resolution obtained through a revolutionary discriminative self-encoderâ€, the authors propose a two-step decoding-encoder-decoder architecture that includes a spatial transformation. The network reverts translation, scaling, and rotation misalignments.
Their method was tested on pre-aligned, synthetically generated LR images from a positive dataset from CelebA. It is worth noting that our network does not attempt to undo the misalignment, but simply learns how to perform super-resolution, and at the same time solve the face structure problem by integrating a feature point location sub-network.

Figure 4: Visual effects in LS3D-W
The most similar research to our method is to perform face super-resolution and dense face correspondence in an alternating manner. Their algorithm was tested on the frontal face images of PubFig and Helen, while the test results on real images (4 in total) were less successful.
The main difference between our "Deep Concatenation Network for Face Illusions" and our research work is that the dense correspondence algorithm (dense correspondence algorithm) is not based on neural networks but is based on cascading regression and is performed from super resolution networks. Separate pre-learning and remain unchanged.
Similarly, the "Deep Cascading Network for Face Illusions" study also faces the same problem, that is, it is necessary to detect feature signatures on the blurred human face, which is particularly evident in the first iteration of the algorithm. On the contrary, we propose to jointly learn super-resolution and facial feature point localization in an end-to-end manner, and use only a single focus to complete the image's super resolution and the positioning of human face feature points. As shown in Figure 2, this leads to a dramatic increase in performance, as we have shown, and produces high-fidelity images throughout the face pose spectrum.

Figure 5: Results from our system, SR-GAN, and CBN on real low resolution human faces from WiderFace.
It is worth noting that our research has surpassed existing technologies and rigorously evaluated super-resolution and face feature points by both quantitative and qualitative methods. Prior to this, people mainly used positive data sets (eg, CelebA, Helen, LFW, and BioID) to draw experimental conclusions. In contrast, the low-resolution images we used in our experiments were created using the newly created LS3D-W. Balanced data sets are generated, where each face pose corresponds to an even number of face images.
We performed a qualitative analysis of 200 real low-resolution images taken from the WiderFace dataset and reached the corresponding conclusions. As far as we know, this is the most comprehensive evaluation of face super-resolution algorithms using real images.
Face alignment
Recently, an assessment of face alignment shows that when the resolution drops below 30 pixels, the optimal performance of medium- and large-sized posture networks trained with standard face resolution (198×192) drops by more than 15% and 30%. This assessment is one of the main goals of our research.
Since our goal is not to propose a new face-alignment architecture, we use Face Alignment Network (FAN), which is constructed from the Hourglass network and residual blocks. . As shown in the figure, FAN can show excellent performance on any face posture and get a clear image.
As we show in the article, a FAN that is specially trained and used to locate feature points in low resolution images does not perform well. One of our contributions is to show that when FAN is integrated and joint training with super-resolution network, FAN can locate facial feature points in low-resolution images with high accuracy.
We proposed Super-FAN: This is the first end-to-end system that integrates face super resolution and feature point location. We use facet alignment through the integrated sub-network and optimize new heat map losses to integrate face structure information into the super-resolution architecture. We show the most advanced face super-resolution and full-face pose alignment. Not only that, we also showed good results on low resolution face images in the real world for the first time.
Withstand high voltage up to 750V (IEC/EN standard)
UL 94V-2 or UL 94V-0 flame retardant housing
Anti-falling screws
Optional wire protection
1~12 poles, dividable as requested
Maximum wiring capacity of 10 mm2
10 amp Terminal Blocks,high quality terminal strips,10 mm2 terminal barriers,high performance terminal connectors,BELEKS T10 series connector strips
Jiangmen Krealux Electrical Appliances Co.,Ltd. , https://www.krealux-online.com