
Figure 1 Wu Shuang (left) and Li Guoqi (right) - two authors of the accepted article
The papers of Wu Shuang, a doctoral student at the Brain Computing Research Center of Tsinghua University, were collected by ICLR2018 and gave verbal reports at the meeting. So far, this is the only oral report article that has been included in the ICLR Conference as the only one of the first signatories in China. The report mainly discusses how to implement training and reasoning for fully discretized deep neural networks and facilitate deployment to embedded devices.
ICLR is the top conference in the field of deep learning. It is also known as the “King of the Untolded†for deep learning. It has attracted the attention and participation of many high-tech companies such as google, Facebook, DeepMind, Amazon and IBM. ICLR2018 was held on April 30, 2018 local time at the Vancouver Convention and Exhibition Center in Canada for a period of 4 days. The conference is chaired by Yoshua Bengio (University of Montreal) and Yann LeCun (New York University & Facebook) among the top three in the in-depth learning field. More than a thousand submissions were received at the conference, of which only 23 were included as Oral report articles for the meeting.
Wu Shuang's report was titled "Training and Inference with Integers in Deep Neural Networks."

Discretized architecture WAGE, training and reasoning combined
The report mainly discusses how to implement training and reasoning for fully discretized deep neural networks and facilitate deployment to embedded devices.
In deep learning, high precision means large areas and high power consumption, which leads to high costs. This deviates from the needs of embedded devices, so hardware accelerators and neuromorphic chips often use low-precision hardware implementations. In terms of low-precision algorithm research, previous work has focused on the reduction of the weight and activation values ​​of the forward inference network so that it can be deployed on hardware accelerators and neuromorphic chips; however, the training of the network still uses high precision. Floating point implementation (GPU). This separation mode of training and reasoning often leads to a lot of extra effort and low-accuracy conversion of the trained floating point network. This not only seriously affects the application deployment of the neural network, but also limits the on-line improvement at the application end.
In order to cope with this situation, this paper proposes a joint discrete architecture WAGE, which for the first time integrates the backward training process and forward reasoning of discrete neural networks into one. Specifically, the network weights, activation values, reverse errors, and weight gradients are all expressed in low-precision integer numbers. In the network training, difficult-to-quantify operations and operands (such as batch normalization, etc.) are eliminated, thereby realizing the entire The training process is completed with integers.
In the actual data set measurement, the WAGE discretization method can effectively improve the test accuracy. Because this method can simultaneously meet the low-power and reverse training requirements of the deep learning accelerator and the neuromorphic chip, it also has the ability to learn online efficiently, and is capable of multi-scene and multi-objective migration and sustainable learning. Smart applications will be of great benefit.
The WAGE framework limits the weights (W), activations (A), gradients (G) and errors (E) in all layers in training and reasoning to low integers. First, for operands, a linear map and a directional hold shift are applied to implement the ternary weights for activation and gradient accumulation of 8-bit integers. Second, for operations, batch normalization is replaced by a constant factor. Other techniques for fine-tuning (such as the SGD optimizer with momentum and L2 regularization) can be simplified or abandoned, and performance degradation is minimal. Taking into account the overall two-way propagation, we completely simplified the reasoning of the cumulative comparison period and trained separately to the low-order multiply-accumulate (MAC) cycles with alignment operations.
The proposed framework was evaluated on MNIST, CIFAR10, SVHN, ImageNet datasets. Compared to the framework of discrete weights and activation only when inference, WAGE has comparable accuracy and can further reduce overfitting. WAGE generates pure bi-directional low-precision integer data streams for DNNs, which can be used for specialized hardware training and reasoning. We released the code on GitHub.
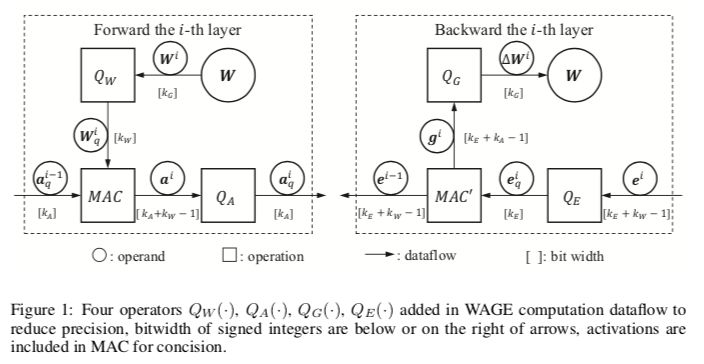
figure 1
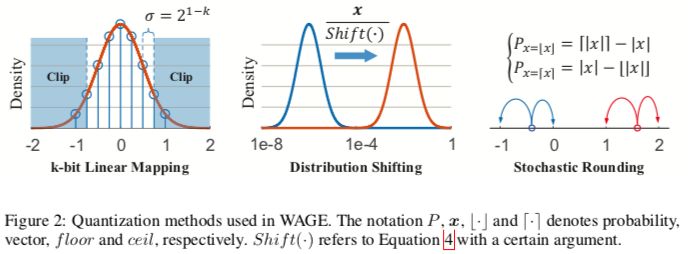
Figure 2: Quantization method for WAGE
Implementation details
MNIST: A variant of LeNet-5. The learning rate η in the WAGE remains at 1 for the entire 100 epochs. We report the average accuracy of the 10 runs on the test set.
SVHN&CIFAR10: The error rate is evaluated in the same way as MNIST.
ImageNet: Using the AlexNe model to evaluate the WAGE framework on the ILSVRC12 dataset.
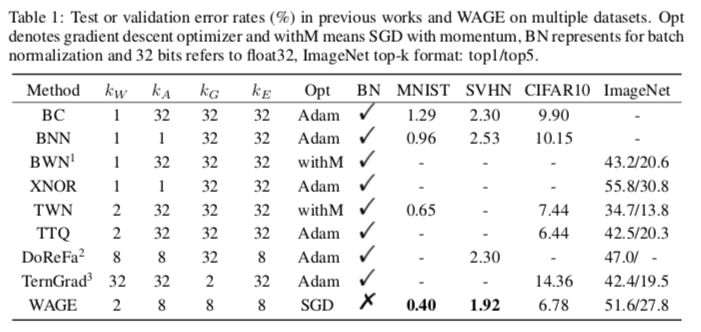
Table 1: Test or verification error rates for multiple datasets for WAGE and other methods (%)
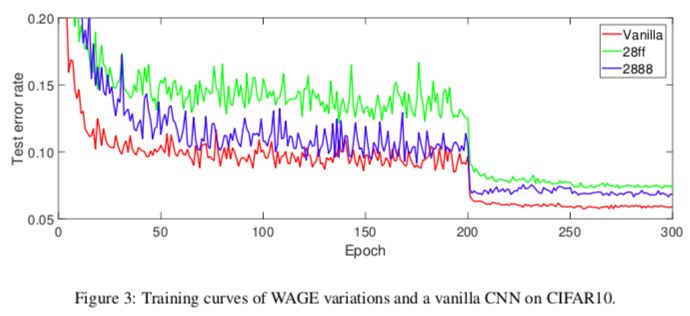
Figure 3: Training curve
Conclusions and future work
The goal of this work is to demonstrate the potential of applying low integer training and reasoning in DNNs. Compared with the FP16, 8-bit integer arithmetic not only reduces the energy consumption and area cost of the IC design (approximately 5 times, see Table 5), but also reduces the memory access cost and memory size requirements during training, which will greatly facilitate the On-site learning capabilities of mobile devices. There are some points that are not involved in this work. Future algorithm development and hardware deployment still need to be improved or solved.

table 5
WAGE enables training and reasoning of DNN pure low-bit integer data streams. We introduce a new initialization method and layered constant scale factor instead of batch normalization, which is a difficult point in network quantification. In addition, the bit width requirements for error calculation and gradient accumulation are also discussed. Experiments show that we can quantify the relative values ​​of gradients and discard most of the small values ​​and their orders of magnitude in backpropagation. Although the accumulation of weight updates is essential for stable convergence and final accuracy, it is still possible to further reduce compression and memory consumption during training. WAGE achieves the highest accuracy in multiple data sets. Through fine-tuning, more efficient mapping, batch normalization and other quantitative methods, there is a certain application prospect for incremental work. In summary, we propose a framework without floating-point representations and show the potential for discrete training and reasoning on integer-based lightweight ASICs or FPGAs with field learning capabilities.
docking station for macbook air,docking station for laptop,docking station usb c,USB C HUB,thunderbolt 3 usb type c hub
Shenzhen Konchang Electronic Technology Co.,Ltd , https://www.konchang.com